知识图谱搭建流程
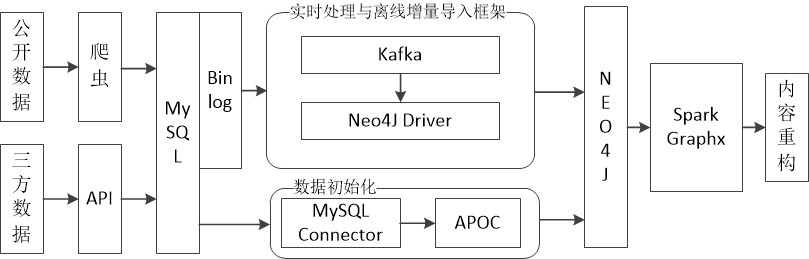
在完成了实体关系的抽取工作之后,得到了处理之后的三元组数据,之后需要将这些数据从原来的关系型数据库中导入到Neo4j图数据库中。根据关系型数据库的结构和Neo4j提供的接口,设计了一个基于Binlog的导入架构模型来搭建知识图谱
其中Binlog是MySQL数据库中记录所有表结构的更新(例如创建、更新表…)以及表数据的修改(插入、更新、删除…)的二进制日志。它不会记录查询和展示这类对数据本身并没有修改的行为。基于这个机制,我们可以使用Canal Server中间件来对Binlog进行监控,当MySQL数据库发生变化时,由Canal Server将数据发送给Canal Client。Canal Client中会有一个Kafka Producer,它是一个消息生产者,能够把消息传输到Kafka消息队列中,由Kafka Consumer消费者从消息队列中取出数据,最后调用一个Neo4j提供的一个接口把数据写到Neo4j中。
数据库结构
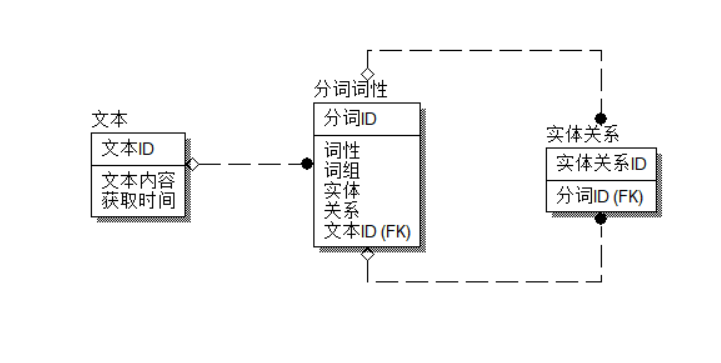
由于存储实体关系三元组需要用到数据库,所以需要对数据库的表结构进行设计,根据对需要存储的数据的特点进行分析,可以得到一下关系:
(1)一个文本信息可以被划分为多个词组,所以文本信息与词组之间时一对多的关系。
(2)一个词组在不同的语境情况下可能存在实体关系两种形态,所以词组和实体关系是一对多的关系。
环境搭建过程
由于在搭建过程中需要使用Kafka和Canal,而这两个工具是在Linux平台下支持的,所以使用时应该先搭建该环境:
(1)安装并启动Zookeeper服务
(2)安装并启动Kafka服务,并创建一个topic
(3)启动生产者进程和消费者进程
(4)编写用于消费和生产数据的客户端代码
(5)搭建Canal环境,并启动Kafka支持,设置其topic值
(6)编写客户端代码,连接MySQL和Neo4j数据库
(7)提取出Binlog中操作的数据库,把数据存入到图数据库中
